
For years, software has been defined by code. Better engineers wrote better logic, and better logic produced better products. Progress was, fundamentally, a function of how well we could design and implement systems.
But AI is changing that equation.
Today, a growing number of breakthroughs in artificial intelligence are no longer driven purely by better algorithms or clever engineering. Instead, they are driven by something far less glamorous—but far more powerful:
Data.
Why Data Has Overtaken Code
Modern AI systems — from large language models to computer vision engines — learn by example, not by instruction. They recognize patterns extracted from data. And that creates a hard constraint:
If the AI training data is incomplete, inconsistent, or poorly labeled, the model inherits those flaws — no matter how advanced the architecture is.
A 2023 survey by Gartner found that poor data quality is the #1 cause of failed AI projects — ahead of algorithms and compute. The implication is clear:
In the age of AI, data is infrastructure.
What "Data Quality" Actually Means
Data quality is often misunderstood as simply "having more data." In reality, it's about having the right data, prepared the right way. That includes accurate data annotation so models understand what they are seeing, rigorous data validation to catch inconsistencies, duplicates, and outliers, and thoughtful collection strategies that ensure diversity, coverage, and real-world relevance. Because a model trained on flawed or biased data will produce unreliable outcomes — regardless of scale.
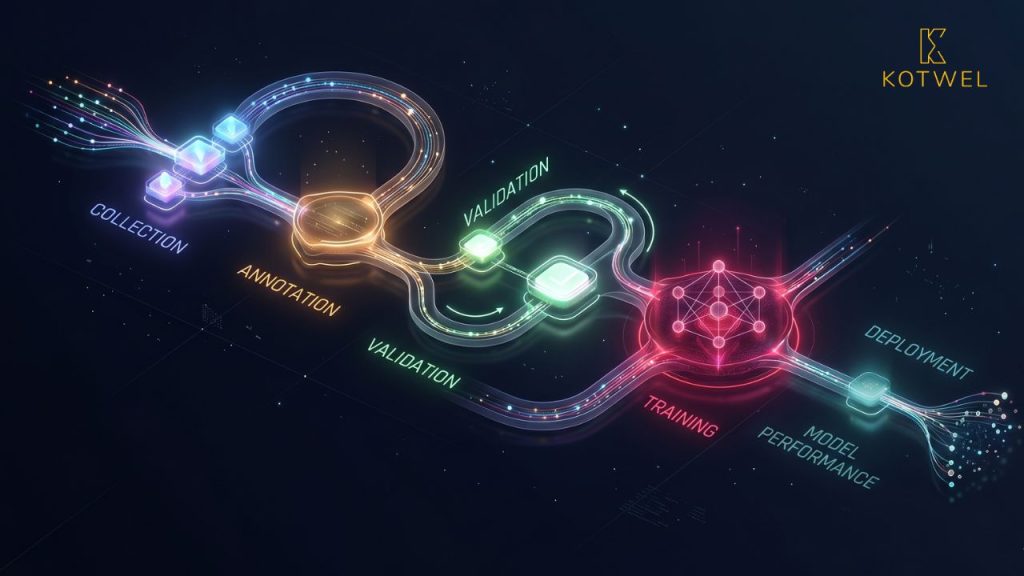
The Shift to Data-Centric AI
Leading AI organizations have begun treating their training datasets the way product companies treat their software: with versioning, governance, quality benchmarks, and dedicated teams. This "data-centric AI" approach — popularized by Andrew Ng — argues that improving data often outperforms model improvements in real-world systems.
Rather than endlessly tweaking model weights, teams are investing in:
- Better labeling workflows
- Clearer annotation guidelines
- More systematic validation pipelines
Companies that treat data as a strategic asset are consistently outperforming those that treat it as an afterthought.
A Quiet but Defining Advantage
As models become more accessible and tooling improves, the competitive edge is moving:
- Not into slightly better architectures
- Not into marginal training gains
But into:
Who can build, maintain, and scale high-quality data systems.
Where We See This Up Close
At Kotwel, we see this shift firsthand. The hardest problems teams face are rarely about model design. They're about getting consistent, high-quality annotations, ensuring datasets reflect real-world complexity, and building pipelines that scale without degrading quality.
In other words:
The real challenge is not building smarter models—
but feeding them better reality.
Code defines how a system learns. Data defines what it learns. And as AI continues to scale, that distinction becomes critical. Because in the end, the difference between AI that works in theory and AI that works in reality is the quality of the data behind it.
In practice, this is where many systems fall short. Not because the models aren't capable — but because the data they learn from doesn't fully reflect the complexity of the real world. Bridging that gap requires annotation that captures meaning (not just labels), validation that ensures consistency at scale, and data collection grounded in real-world scenarios.
This is the layer we're deeply focused on at Kotwel:
Turning real-world complexity into data that AI systems can actually learn from.
Because ultimately, reliable AI isn't just built on better models. It's built on better representations of reality.
![]()
Kotwel is a reliable data service provider, offering custom AI solutions and high-quality AI training data for companies worldwide. Data services at Kotwel include data collection, data labeling (data annotation) and data validation that help get more out of your algorithms by generating, labeling and validating unique and high-quality training data, specifically tailored to your needs.
Frequently Asked Questions
You might be interested in:

Computer Vision is a subset of artificial intelligence (AI) that equips computers with the capability to see, understand, and interpret the visual world. Utilizing digital images from cameras and videos along with deep learning models, machines can accurately identify and classify objects, responding based […]

Deep learning has revolutionized the field of computer vision, offering robust solutions that mimic human visual perception abilities. This technology is now fundamental in various industries, from enhancing healthcare diagnostics to powering autonomous vehicles. Here’s how deep learning is applied across different sectors: Healthcare […]

Ensuring the quality of data labeling is crucial in developing reliable machine learning models. This article outlines best practices in quality assurance for data labeling, emphasizing error detection, consensus building among labelers, and quality control measures to maintain data integrity. 1. The Important Role […]